![]()
|
|
|
Předchozí metody byly založeny za opakovaném prohledávání pole - nejprve všech n prvků, potom n-1 prvků atd. Pokud se nám nepodaří snížit počet prohledávání, bude počet porovnání vždy řádu O(n2). Přitom by se mohlo zdát, že stačí pouhé jedno prohledání pole, neboť při něm už získáme všechny potřebné informace. Je zřejmé, že všechny předchozí metody informací příliš optimálně nevyužívaly. Pokusíme se tedy
navrhnout metodu, která bude využívat informací poněkud efektivněji. Rozdělíme-li prvky v
poli na dvojice, můžeme pomocí n/2
porovnání určit menší prvek z každé dvojice. Pomocí dalších n/4
porovnání určíme menší prvek z každé čtveřice (stačí porovnat menší
prvky z každé dvojice) atd. Takto můžeme pomocí n-1
porovnání sestrojit porovnávací strom
, jehož kořen obsahuje nejmenší prvek celého
pole a kořen každého podstromu obsahuje nejmenší prvek tohoto podstromu. Příklad 7.1
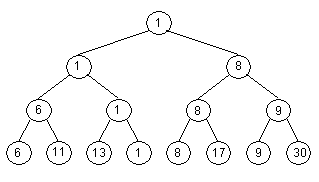
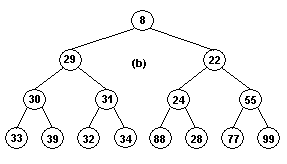
Provnávací strom, zkonstruovaný z posloupnosti (6, 11, 13, 1, 8, 17, 9, 30) vidíme na obr. 7.1.
Nyní z celého stromu odstraníme nejmenší prvek. List, který tuto hodnotu obsahoval, nahradíme vrcholem s klíčem +¥ , a ostatní vrcholy porovnávacího stromu, které obsahovaly nejmenší hodnotu, nahradíme vždy druhým z dvojice vrcholů, ve které se tato hodnota vyskytovala. Nyní můžeme odstranit druhý nejmenší prvek atd. Odstraněné hodnoty tvoří posloupnost seřazenou podle velikosti. Stromové třídění skončí v okamžiku, kdy vrcholu přiřadíme hodnotu + ¥. Příklad 7.1
(pokračování)
V porovnávacím stromu na
obr. 7.1
je nejmenší hodnota 1.
List, který ji obsahoval, nahradíme listem s hodnotou +¥
. Předchůdce tohoto listu bude obsahovat
hodnotu 13,
předchůdce na úrovni 2 bude obsahovat hodnotu 6
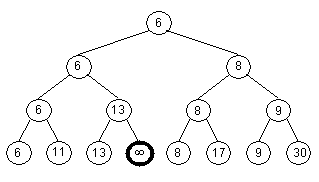
a kořen pak taky 6. Strom, který vznikne touto úpravou, vidíme na obr. 7.2.
V následujícím kroku odstraníme hodnotu 6
a do kořene se dostane 8.
Další kroky jistě zvládne čtenář sám.
Na sestrojení stromu jsme potřebovali n kroků; na jednotlivé výběry potřebujeme log2n kroků (počet těchto kroků je roven počtu úrovní stromu). Protože výběrů ze stromu je celkem n, dostáváme, že stromové třídění potřebuje O(n.log2n) kroků. Pro velká n tedy bude výhodnější než Shellovo třídění, které vyžaduje O(n1,2) kroků. Podívejme se nyní na
nevýhody stromového třídění. Tento algoritmus potřebuje celkem 2n-1
paměťových míst, zatímco všechny předchozí metody potřebovaly pouze n
míst. Navíc v závěru stromového třídění se strom zaplní vrcholy s
hodnotou +¥
, které se naprosto zbytečně porovnávají. Obě tyto nevýhody se
pokouší odstranit metoda třídění
haldou
(heapsort),
kterou navrhl J. Williams. Halda
je zde vlastně binární strom, v němž
jsou uložená data jistým způsobem uspořádána a který je uložen v poli.
Formální definice haldy zní: Halda je posloupnost
prvků hl, hl+1,
... , hr
takových, že pro všechny indexy i =
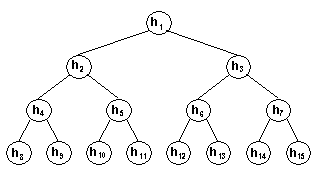
l, ... , r/2 platí nerovnosti hi £ h2i, hi £ h2i+1 (10) Uvažujme haldu h1, h2, ... , hn. Pak je h11 kořenem stromu a h2 a h3 jsou jeho levý a pravý následovník. Vrchol h2 má následovníky h4 a h5, vrchol h3 má následovníky h6 a h7. Viz též obr. 7.2
Vezměme nyní prvky al, ..., an
tříděného pole a.
Je-li l
n/2,
tvoří podle definice haldu, neboť ve tříděném poli pro žádný index i
= n/2 .. n
neexistuje a2i
nebo a2i+1. Tyto prvky představují vlastně nejnižší úroveň binárního stromu.
Abychom toho mohli využít, potřebujeme ukázat, jak přidat do haldy nový
prvek. Přidejme k haldě al+j, ..., an
prvek al.
Nově přidaný prvek v posloupnosti al, ..., an je na místě kořene (nemusí
jít o kořen celého stromu, ale nějakého podstromu). Podíváme se, zda pro
něj platí podmínky (10).
Pokud ano, je vše v pořádku a posloupnost al, ..., an stále tvoří haldu. Pokud
ne, musíme tento prvek prohodit s menším z jeho následovníků tak, aby byly
podmínky (10)
splněny. Nyní opět zkontrolujeme, zda platí podmínky (10);
pokud ne, musíme nově vložený prvek opět zaměnit s některým z následovníků
atd. Nově vložený prvek
tedy posunujeme z původní polohy v kořeni stromu na nižší úrovně tak,
aby platily podmínky (10),
které definují haldu.
Příklad 7.2
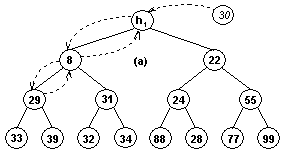
Uvažujme haldu z obr. 7.3
(a), kterou tvoří vlastně dva samostatné podstromy. Do této haldy chceme přidat
prvek s hodnotou 30. Nejprve jej vložíme na pozici h1,
takže se stane kořenem stromu. Protože ale nesplňuje podmínky (10),
musíme jej prohodit s menším z jeho následovníků , který má hodnotu 8.
Ani zde nejsou podmínky (10)
splněny, proto jej opět prohodíme s menším
z následovníků (má hodnotu 29). Výsledek vidíme na obr. 7.3
(b).
Jakmile umíme přidat
do haldy nový prvek, umíme vytvořit haldu z prvků celého pole: 1. Vyjdeme od prvků al, ..., an tříděného pole a
pro l = [n/2]+1; tyto prvky
tvoří haldu. 2. K části haldy, která je již hotová, postupně přidáme
prvky l-1, l-2,
... , 1. Proceduru, která přidá jeden prvek do haldy,
nazveme výstižně VytvořHaldu, neboť
s její pomocí haldu opravdu vytvoříme. procedure
VytvořHaldu(l,r: integer); label
13; var
i,j: index; x:
prvek; begin i := l; j := 2*i; x := a[i];
{přidávaný prvek} while j
<= r do begin
{V tomto cyklu se x zařadí} if
j < r then
{Porovnat s menším z} if
a[j].klíč > a[j+1].klíč then inc(j);
{následovníků} if
x.klíč <= a[j].klíč then goto 13; {x je větší - konec} a[i]
:= a[j]; i := j; j := 2*i end; 13: a[i]
:= x; end;{vytvoř
haldu} Haldu vytvoříme opakovaným voláním této procedury pro l = [n/2], [n/2]-1,
... , 1. Ve vytvořené haldě bude na prvním místě nejmenší prvek ze tříděného
pole; další prvky však již seřazené nejsou. Proto budeme celý postup
opakovat pro prvky a2, ..., an:
vytvoříme z nich haldu, která bude mít na prvním místě (tj. ve druhé
pozici tříděného pole) nejmenší hodnotu zbylé části posloupnosti. V dalším
kroku pak vytvoříme haldu z prvků a3,
..., an
atd. Zde ovšem vytváříme
haldu z n prvků, pak haldu z n-1
prvků atd. Výhodnější bude, jestliže po prvním kroku, po vytvoření
haldy z n prvků, uklidíme nalezený
nejmenší prvek na konec pole, tj. vyměníme první prvek s posledním. Snadno
se přesvědčíme, že pokud prvky a1,
..., an tvořily
haldu, tvoří ji i prvky a2, ..., an-1. Proto nyní bude stačit
přidat k této haldě an a
dostaneme haldu tvořenou a2, ..., an. Druhý nejmenší prvek
pole, který bude v kořeni této haldy, opět "uklidíme na konec",
vyměníme ho s předposledním prvkem pole atd. Příklad 7.3
Uvažujme posloupnost
(3,
5,
8,
2,
1,
4,
7,
6
). Základem haldy
budou prvky s indexy 5 - 8. k nim postupně přidáme prvky s indexy 4, 3, 2 a 1
a vytvoříme tak haldu
(1,
2,
4,
3,
5,
8,
7,
6
). Nyní "uklidíme"
nalezený nejmenší prvek na konec pole, tj. prohodíme ho s posledním prvkem.
Tak dostaneme posloupnost
(6,
2,
4,
3,
5,
8,
7,
1
). Protože prvky 2,
4, 3,
5, 8,
7 tvoří haldu,
stačí k ní přidat prvek 6. (Nyní vytváříme
samozřejmě haldu pouze z prvních n-1
prvků.). Po zařazení prvku 6 do haldy pomocí
procedury VytvořHaldu
dostaneme posloupnost
(2,
3,
4,
6,
5,
8,
7,
1
). Ve zbylé
posloupnosti je tedy nejmenší hodnota 2. To opět
"uklidíme" na konec, vyměníme ji za předposlední prvek a
dostaneme
(7,
3,
4,
6,
5,
8,
2,
1
). Je tedy třeba přidat
k haldě tvořené prvky a[2]..a[6]
prvek 7... atd. Výsledkem bude pole, seřazené
obráceně:
(8,
7,
6,
5,
4,
3,
2,
1
).
Popsaný postup vede k
poli, seřazeném v obráceném pořadí. Pokud si přejeme pole, seřazené od
nejmenšího prvku k největšímu (jako ve všech předchozích metodách), stačí
prostě obrátit nerovnosti v proceduře VytvořHaldu
(tedy vlastně obrátit nerovnosti v definici haldy ve vztazích (10)). Vyložený postup
zachycuje procedura TříděníHaldou.
Jejím jádrem je procedura VytvořHaldu
se změněnými nerovnostmi. procedure
VytvořHaldu(l,r: integer); label
13; var
i,j: index; x:
prvek; begin i := l; j := 2*i; x := a[i]; while j
<= r do begin
{Zařadí x na místo} if
j < r then
{Porovnání s větším} if
a[j].klíč < a[j+1].klíč then inc(j);
{prvkem} if
x.klíč >= a[j].klíč then goto 13; {Jsou-li násl. menší} a[i]
:= a[j]; i := j; j := 2*i
{tak konec} end; 13: a[i]
:= x; end;{vytvoř haldu}
procedure
TříděníHaldou; var
l, r: index; x:
prvek; begin l := (n
div 2) + 1;
{Prvky s indexy l..r} r := n;
{již tvoří haldu} while l
> 1 do begin dec(l);
{Přidávání prvků k haldě} VytvořHaldu(l,r) end; while r
> 1 do begin
{Nalezený nejmenší prvek dej} x
:= a[1];
{na konec pole} a[1]
:= a[r]; a[r]
:= x;
{a ze zbytku zase} dec(r); VytvořHaldu(1,r)
{vytvoř haldu} end end;{třídění haldou} Analýza třídění haldou
Proceduru VytvořHaldu budeme volat při počátečním vytvoření haldy n/2-krát. Počet míst, přes které se budou při jednotlivých voláních přemísťovat vkládané prvky, bude postupně [log2(n/2)], [log2(n/2+1)], ... , [log2(n-1)]. Celkem jde tedy o méně než (n/2)log2n přesunů při konstrukci haldy. Vlastní třídění
(cyklus while r > 1 v proceduře TříděníHaldou)
vyžaduje n - 1 průchodů. Jednotlivá
volání procedury VytvořHaldu v
tomto cyklu vyžadují nejvýše [log2(n-1)],
[log2(n-2)],
... , 1 přesunů; celkem půjde přibližně o (n-1)(log2(n-1)-s)
přesunů, kde s = log2e
= 1,44269... (viz vztah (5) v oddílu o třídění binárním
vkládáním). Vedle toho potřebujeme při každém průchodu tímto cyklem 3 přesuny
na přemístění nalezeného prvku na konec pole, tedy celkem dalších 3(n-1) přesunů. Z toho plyne, že v
celkový počet přesunů je O(n.log2n). To je výsledek lepší než u Shellova algoritmu. Na druhé straně je první pohled je zřejmé, že jednotlivé kroky třídění haldou jsou složitější než tomu bylo u předchozích metod. Např. největší prvek se po vytvoření haldy dostane na první místo a teprve pak jej odsuneme na správné místo na konci pole. Z toho plyne, že třídění haldou bude výhodné zejména pro rozsáhlá pole, kde se výrazně uplatní malý počet operací.
|
|
|