![]()
|
|
|
Příčinou neefektivnosti některých z předchozích algoritmů, např. třídění přímým vkládáním nebo bublinkového třídění, je, že v nich vyměňujeme pouze sousední prvky. Pokud je například nejmenší prvek uložen na konci pole, potřebujeme n výměn, aby se dostal na správné místo. Proto se některé algoritmy snaží preferovat výměny prvků "na velké vzdálenosti". Jedním z takových algoritmů je i Shellovo třídění (Shellsort), navržené D. L. Shellem. Základní myšlenkou
Shellova třídění je přeuspořádat pole tak, že když vezmeme každý h-tý
prvek, dostaneme setříděné pole (takovéto pole se nazývá setříděné
s krokem h). Pole setříděné s krokem h
představuje vlastně h proložených
nezávislých polí. Při třídění pole s
krokem h můžeme přesunovat prvky na
větší vzdálenosti (nejméně h) a
tak dosáhnout menšího počtu výměn při třídění s menším krokem. Při
Shellově třídění tedy utřídíme pole s krokem h1,
pak s krokem h2
< h1 atd.; nakonec je utřídíme
s krokem 1 a dostaneme plně utříděné pole. Při každém z následujících
průchodů třídíme pole, které je již částečně setříděné, a proto
můžeme očekávat, že bude třeba jen málo výměn. Dosud jsme neurčili,
jak utřídíme pole s krokem h. Použijeme
např. metody přímého vkládání
. Při formulaci algoritmu přímého vkládání
použili zarážku, abychom zjednodušili
podmínku pro ukončení průchodu polem. Budeme-li chtít použít zarážek
i v Shellově třídění, musíme jich zavést
více. Je-li ht největší z kroků, se
kterými dané pole a třídíme, musíme
je deklarovat příkazem var
a: array [-ht..n] of prvek; Pro větší hodnoty ht to nemusí být výhodné. V následující proceduře Shell zarážky nepoužijeme. Čtenář jistě dokáže napsat proceduru, využívající zarážek sám. V této proceduře předpokládáme, že t je globální konstanta, udávající počet různých kroků pro třídění. procedure
Shell; var
i,j,k: index; x:
prvek; m:
1..t; h:
array [1..t] of integer;
{pole délek kroků} begin h[t] := 1;
{výpočet posloupnosti kroků} for i :=
t-1 downto 1 do h[i] := 3*h[i+1]+1; for m := 1
to t do begin{třídění s krokem h[m]} k
:= h[m];
{krok} for
i := k+1 to n do begin
{přímé vkládání} x
:= a[i]; j
:= i-k; while
(x.klíč < a[j].klíč) and (j >= k) do begin
a[j+k] := a[j];
{bez zarážky}
j := j-k; end; a[j+k]
:= x; end end end; Příklad 6.1
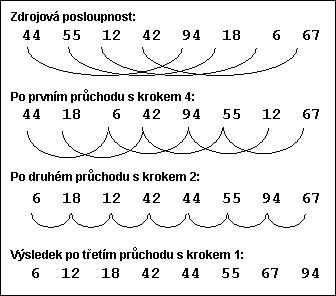
Podívejme se opět na posloupnost (44, 55, 12, 42, 9, 18, 6, 67). Zkusíme ji utřídit pomocí Shellova algoritmu; přitom zvolíme t = 3 a kroky h1 = 4, h2 = 2 a h3 = 1. Jak se dále dozvíme, nejde o příliš výhodnou volbu; pro náš příklad ale postačí.
Obr.
6.
1 Shellovo třídění (třídění se zmenšováním
kroku) Analýza Shellova třídění
Analýza Shellova třídění vede ke komplikovaným matematickým problémům, které přesahují rámec tohoto textu. Uvedeme proto pouze některé výsledky. První z problémů, o
kterých se zmíníme, je volba posloupnosti kroků hi.
Otázka optimální volby není, jak se zdá, dosud uspokojivě vyřešena. Je však
známo, že obecně horší výsledky dostaneme, jestliže bude hi násobkem
hi-1. Např. posloupnost ...,
8, 4, 2, 1 nevede k příliš efektivnímu třídění, neboť při této volbě
porovnáme prvky na sudých místech s prvky na lichých místech až v posledním
průchodu. Na druhé straně je známo,
že poměrně dobré výsledky dostaneme pro posloupnost kroků definovanou
vztahy ht = 1, hk-1
= 3hk+1; t
volíme podle vztahu t = [log3n] - 1, kde [z] opět označuje
celou část čísla z. Poslední
prvky této posloupnosti jsou 1, 4, 13, 40, 121, ... Lze dokázat, že pro
tuto volbu kroků nepřesáhne počet porovnání hodnotu n3/2. Jiná doporučovaná posloupnost má tvar ht = 1, hk-1 = 2hk+1; v tomto případě určíme t ze vztahu t = [log2n] - 1. Tato posloupnost končí čísly 1, 3, 7, 15, 31, ... Celková složitost
Shellova algoritmu v tomto případě je O(n1,2).
|
|
|